What you’ve described would be like looking at a chart of various fluid boiling points at atmospheric pressure and being like “Wow, water boils at 100 C!” It would only be interesting if that somehow weren’t the case.
Where is the “Wow!” in this post? It states a fact, like “Water boils at 100C under 1 atm”, and shows that the student (ChatGPT) has correctly reproduced the experiment.
Why do you think schools keep teaching that “Water boils at 100C under 1 atm”? If it’s so obvious, should they stop putting it on the test and failing those who say it boils at “69C, giggity”?
Derek feeling the need to comment that the bias in the training data correlates with the bias of the corrected output of a commercial product just seemed really bizarre to me. Maybe it’s got the same appeal as a zoo or something, I never really got into watching animals be animals in a zoo.
Hm? Watching animals be animals at a zoo, is a way better sampling of how animals are animals, than for example watching that wildlife “documentary” where they’d throw lemmings of a cliff “for dramatic effect” (a “commercially corrected bias”?).
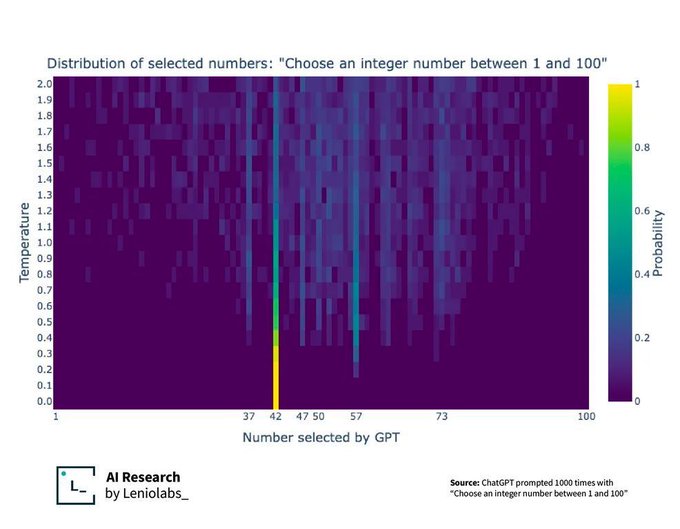
In this case, the “corrected output” is just 42, not 37, but as the temperature increases on the Y axis, we get a glimpse of internal biases, which actually let through other patterns of the training data, like the 37.
“we don’t need to prove the 2020 election was stolen, it’s implied because trump had bigger crowds at his rallies!” -90% of trump supporters
Another good example is the Monty Hall “paradox” where 99% of people are going to incorrectly tell you the chance is 50% because they took math and that’s how it works.
Just because something seems obvious to you doesn’t mean it is correct. Always a good idea to test your hypothesis.
Trump Rallies would be a really stupid sample data set for American voters. A crowd of 10,000 people means fuck all compared to 158,429,631. If OpenAI has been training their models on such a small pool then I’d call them absolute morons.
A crowd of 10,000 people means fuck all compared to 158,429,631.
I agree that it would be a bad data set, but not because it is too small. That size would actually give you a pretty good result if it was sufficiently random. Which is, of course, the problem.
But you’re missing the point: just because something is obvious to you does not mean it’s actually true. The model could be trained in a way to not be biased by our number choice, but to actually be pseudo-random. Is it surprising that it would turn out this way? No. But to think your assumption doesn’t need to be proven, in such a case, is almost equivalent to thinking a Trump rally is a good data sample for determining the opinion of the general public.

{kind=link}
Why would that need to be proven? We’re the sample data. It’s implied.
The correctness of the sampling process still needs a proof. Like this.
What you’ve described would be like looking at a chart of various fluid boiling points at atmospheric pressure and being like “Wow, water boils at 100 C!” It would only be interesting if that somehow weren’t the case.
Where is the “Wow!” in this post? It states a fact, like “Water boils at 100C under 1 atm”, and shows that the student (ChatGPT) has correctly reproduced the experiment.
Why do you think schools keep teaching that “Water boils at 100C under 1 atm”? If it’s so obvious, should they stop putting it on the test and failing those who say it boils at “69C, giggity”?
Derek feeling the need to comment that the bias in the training data correlates with the bias of the corrected output of a commercial product just seemed really bizarre to me. Maybe it’s got the same appeal as a zoo or something, I never really got into watching animals be animals in a zoo.
Hm? Watching animals be animals at a zoo, is a way better sampling of how animals are animals, than for example watching that wildlife “documentary” where they’d throw lemmings of a cliff “for dramatic effect” (a “commercially corrected bias”?).
In this case, the “corrected output” is just 42, not 37, but as the temperature increases on the Y axis, we get a glimpse of internal biases, which actually let through other patterns of the training data, like the 37.
“we don’t need to prove the 2020 election was stolen, it’s implied because trump had bigger crowds at his rallies!” -90% of trump supporters
Another good example is the Monty Hall “paradox” where 99% of people are going to incorrectly tell you the chance is 50% because they took math and that’s how it works.
Just because something seems obvious to you doesn’t mean it is correct. Always a good idea to test your hypothesis.
Trump Rallies would be a really stupid sample data set for American voters. A crowd of 10,000 people means fuck all compared to 158,429,631. If OpenAI has been training their models on such a small pool then I’d call them absolute morons.
I agree that it would be a bad data set, but not because it is too small. That size would actually give you a pretty good result if it was sufficiently random. Which is, of course, the problem.
But you’re missing the point: just because something is obvious to you does not mean it’s actually true. The model could be trained in a way to not be biased by our number choice, but to actually be pseudo-random. Is it surprising that it would turn out this way? No. But to think your assumption doesn’t need to be proven, in such a case, is almost equivalent to thinking a Trump rally is a good data sample for determining the opinion of the general public.